
What is a robots.txt file?
A robots.txt file is a file that webmasters create to instruct web robots (also known as spiders, crawlers, or bots) how to crawl and index pages on their website. It is essentially a set of instructions that tell search engines which pages or sections of a website they should or shouldn’t crawl.
The robots.txt file is a simple text file that is placed in the root directory of a website. The file contains a set of instructions that specify which robots are allowed to crawl certain pages, directories or files on the website, and which robots are disallowed.
Basic format of Robots.txt file :
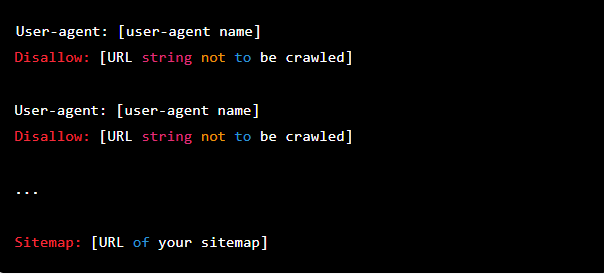
Here’s a quick rundown of each component of robots.txt file:
User-agent: This identifies the web robot to whom the instructions are directed. You could, for example, use * as a wildcard to apply the rule to all bots, or you could specify a specific bot like Googlebot or Bingbot.
Allow: The URL string that should not be crawled is specified here. You can specify specific URLs that should not be crawled or use * as a wildcard to block all URLs on the site.
Sitemap: The URL of the sitemap is specified here.
Here are a few examples of robots.txt in action for a www.example.com site:
- Providing access to all content to all web crawlers
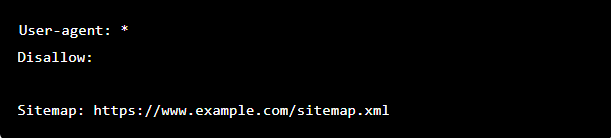
In a robots.txt file, this syntax instructs web crawlers to crawl all webpage on www.example.com, including homepage.
-
Blocking a specific web crawler from a specific folder

This syntax instructs only Google’s crawler (user-agent name Googlebot) to avoid crawling any pages containing the URL string www.example.com/example- [ FOLDER NAME ]
- preventing a specific web crawler from accessing a specific web page

This tells the Baiduspider web crawler not to crawl the /private.html page on your website.
How does Robots.txt work?
Robots.txt is a text file that websites use to tell web robots (also known as web crawlers or spiders) how to interact with the site. Web robots are automated programmes that crawl the internet and collect data for search engines or other purposes such as web indexing or data mining.
The robots.txt file is placed in the website’s root directory and contains a set of rules for web robots to follow. When a web robot visits a website, it first searches for the robots.txt file to see if it contains any instructions.
Some instant robots.txt tips:
- The robots.txt file is case-sensitive. User-agent, Disallow, and Allow must be in lowercase.
- A single robots.txt file can contain multiple records, each targeting a specific web robot. For example, you can have a record for Googlebot and a separate record for Bingbot.
- If a web robot encounters a robots.txt file that it doesn’t understand, it will assume that it’s allowed to access all URLs on the website.
- The Allow field can be used to override a Disallow directive. For example, if you have a Disallow rule for a specific folder but an Allow rule for a subfolder within that folder, the web robot will be allowed to access the subfolder
- The robots.txt file can also include directives for other website-related tasks, such as setting crawl delay or specifying the location of the website’s sitemap.
While the robots.txt file can assist in controlling web robot access to your website, it is not a foolproof method of keeping pages out of search engine indexes or from being found by other means. Other methods, such as password protection or server-level access controls, may be required if you need to restrict access to specific pages.
To enhance your knowledge on robots.txt file and how it’s works then , consider attending our Digital Marketing and Growth Hacking session. Register for the webinar now by clicking on the link below.
https://premiumlearnings.com/contact/
You can also download premium learning’s app from the link below
https://play.google.com/store/apps/details?id=com.premiumlearnings.learn&hl=en
